
Today we are going to talk about another form of machine learning known as unsupervised machine learning. If in supervised learning we trained the model with sample data that included the question (predictor variables) and the answer (response variable) for predictive purposes, unsupervised learning has a descriptive purpose: we do not have any response, and we want the machine to find patterns, similarities, or differences between the data, to identify possible clusters. There are many uses, such as customer segmentation, categorizing users of a social network, or recommending to a customer what other customers, who behave in a similar way, have bought.
This thing of feeding data to a machine so it tells us what patterns or associations it has found may sound mysterious, but it really is not so, because the clustering algorithms depend on the definition of similarity or distance that we decide to apply, which will even be able to compare apples and oranges, as long as it meets very simple requirements*, and there are techniques that allow to transform apparently complex spaces, like image D, into simple spaces where grouping is easier, like image A.
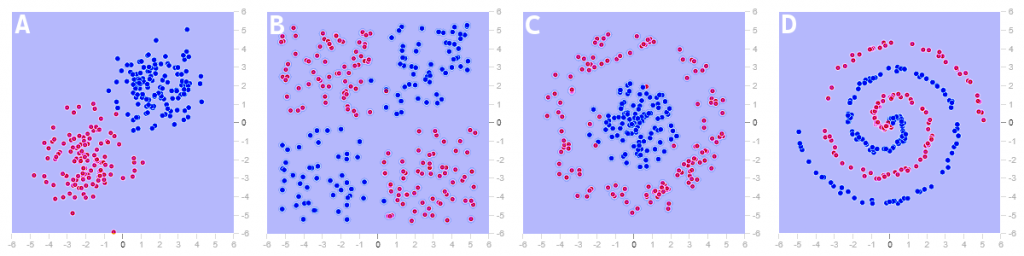
These images show (more or less) simple geometric spaces, but many times our data do not lend themselves to such a simple representation. Imagine that we are processing information on the commercial activity with our customers to make an automatic segmentation, combining data such as the product families they buy, their average purchase volume, by which channel they contact us, how often… With a good data scientist we will define a similarity function that will be quite complex, we will be able to find clusters automatically, and at most we will have a very simplified graphical view, on a couple of variables, of our clusters, but we can trust that , if you have done a good job of understanding the details of the business, that grouping will be relevant to the activity. It may look obscure, but the algorithm has only looked for which elements look like other elements based on our criteria, no matter how complex these are.
There is also something called semi-supervised learning, similar to supervised learning, but it is applied when we only have the response variable for a small sample of our data. It uses techniques similar to grouping to fill in the missing variable. If we have, for example, a sample of transactions labeled as fraudulent or non-fraudulent, with a semi-supervised learning algorithm, we can group all our transactions around one or another cluster, by similarity.
In summary, unsupervised learning is sort of an automatic “birds of a feather flock together”, with many applications in business.
* If there is a mathematician in the room, the requirements will be immediately recognizable: the distance function must always be non-negative (the distance between two samples is always greater than or equal to 0), symmetric (the distance from M to N is the same as from N to M), triangular (the distance from M to P must be less than or equal to that from M to N plus that from N to P), and the distance of a sample to itself is null.